文章引用:http://blog.sina.com.cn/s/blog_62a9902f0101cjl3.html
Latent Semantic Analysis (LSA)也被称为Latent Semantic Indexing(LSI),理解就是通过分析文档去发现这些文档中潜在的意思和概念。
如果每一个词仅表示一个概念。而且每一个概念只被一个词所描写叙述。LSA将很easy(从词到概念存在一个简单的映射关系)
不幸的是,这个问题并没有如此简单。由于存在不同的词表示同一个意思(同义词)。一个词表示多个意思,全部这样的二义性(多义性)都会混淆概念以至于有时就算是人也非常难理解。
比如,银行这个词和抵押、贷款、利率一起出现时往往表示金融机构。可是,和鱼饵,投掷、鱼一起出现时往往表示河岸。
潜语义分析工作原理
潜语义分析(Latent SemanticAnalysis)源自问题:怎样从搜索query中找到相关的文档。当我们试图通过比較词来找到相关的文本时。存在着难以解决的局限性,那就是在搜索中我们实际想要去比較的不是词,而是隐藏在词之后的意义和概念。潜语义分析试图去解决问题,它把词和文档都映射到一个‘概念’空间并在这个空间内进行比較(注:也就是一种降维技术)。
当文档的作者写作的时候,对于词语有着很宽泛的选择。
不同的作者对于词语的选择有着不同的偏好,这样会导致概念的混淆。
这种对于词语的随机选择在词-概念 的关系中引入了噪音。
LSA滤除了这种一些噪音。而且还可以从所有的文档中找到最小的概念集合(为什么是最小?)。
为了让这个难题更好解决,LSA引入一些重要的简化:
1. 文档被表示为”一堆词(bags of words)”,因此词在文档中出现的位置并不重要,仅仅有一个词的出现次数。
2.概念被表示成常常出如今一起的一些词的某种模式。比如“leash”(栓狗的皮带)、“treat”、“obey”(服从)常常出如今关于训练狗的文档中。
3.词被觉得仅仅有一个意思。这个显然会有反例(bank表示河岸或者金融机构),可是这能够使得问题变得更加easy。(这个简化会有如何的缺陷呢?)
接下来看一个LSA的小样例。Next Part:
一个简单的小样例一个小样例。我在amazon.com上搜索”investing”(投资) 而且取top10搜索结果的书名。当中一个被废弃了,由于它仅仅含有一个索引词(indexword)和其他标题同样。
索引词能够是不论什么满足下列条件的词:
1. 在2个或者2个以上标题中出现 而且
2. 不是那种特别常见的词比如 “and”, ”the” 这样的(停用词-stopword)。
这样的词没有包括进来是由于他们本身不存在什么意义。
在这个样例中,我们拿掉了例如以下停用词:“and”, “edition”, “for”, “in”,“little”, “of”, “the”, “to”.
以下就是那9个标题,索引词(在2个或2个以上标题出现过的非停用词)被下划线标注:
1. The Neatest Little Guide toStock Market Investing
2. Investing For Dummies, 4th Edition
3. The Little Book of Common SenseInvesting: The OnlyWay to Guarantee Your Fair Share ofStock Market Returns
4. The Little Book ofValue Investing
5. ValueInvesting: From Graham to Buffett and Beyond
6. RichDad's Guide toInvesting: What theRich Invest in,That the Poor and the Middle Class Do Not!
7. Investing in Real Estate, 5th Edition
8. StockInvesting ForDummies
9. RichDad's Advisors: The ABC's ofReal Estate Investing: TheSecrets of Finding Hidden Profits Most Investors Miss
在这个样例里面应用了LSA,我们能够在XY轴的图中画出词和标题的位置(仅仅有2维)。而且识别出标题的聚类。蓝色圆圈表示9个标题,红色方块表示11个索引词。我们不但能够画出标题的聚类。而且因为索引词能够被画在标题一起。我们还能够给这些聚类打标签。
比如,蓝色的聚类。包括了T7和T9。是关于realestate(房地产)的,绿色的聚类。包括了标题T2,T4,T5和T8。是讲valueinvesting(价值投资)的,最后是红色的聚类。包括了标题T1和T3,是讲stockmarket(股票市场)的。标题T6是孤立点(outlier)
")
LSA的第一步是要去创建词到标题(文档)的矩阵。在这个矩阵里,每个索引词占领了一行,每个标题占领一列。每个单元(cell)包括了这个词出如今那个标题中的次数。比如,词”book”出如今T3中一次。出如今T4中一次,而”investing”在全部标题中都出现了一次。一般来说,在LSA中的矩阵会很大并且会很稀疏(大部分的单元都是0)。这是由于每个标题或者文档一般仅仅包括全部词汇的一小部分。更复杂的LSA算法会利用这样的稀疏性去改善空间和时间复杂度。
在这篇文章中。我们用python代码去实现LSA的全部步骤。我们将介绍全部的代码。Python代码能够在这里被下到(见上)。须要安装NumPy和 SciPy这两个库。
NumPy是python的数值计算类,用到了zeros(初始化矩阵)。scipy.linalg这个线性代数的库中。我们引入了svd函数也就是做神秘值分解,LSA的核心。
- fromnumpy importzeros
- from scipy.linalgimport svd
- titles =
- [
- "The Neatest Little Guide to Stock MarketInvesting",
- "Investing For Dummies, 4thEdition",
- "The Little Book of Common SenseInvesting: The Only Way to Guarantee Your Fair Share of StockMarket Returns",
- "The Little Book of ValueInvesting",
- "Value Investing: From Graham to Buffettand Beyond",
- "Rich Dad's Guide toInvesting: What the Rich Invest in, That the Poor and the MiddleClass Do Not!",
- "Investing in Real Estate, 5thEdition",
- "Stock Investing ForDummies",
- "Rich Dad's Advisors: The ABC's of RealEstate Investing: The Secrets of Finding Hidden Profits MostInvestors Miss"
- ]
- stopwords = ['and','edition','for','in','little','of','the','to']
- ignorechars = ''''',:'!'''
- classLSA(object):
- def__init__(self,stopwords, ignorechars):
- self.stopwords =stopwords
- self.ignorechars =ignorechars
- self.wdict ={}
- self.dcount =0
相当于建了一下倒排。
- defparse(self,doc):
- words = doc.split(); for w inwords:
- w = w.lower().translate(None, self.ignorechars)
- if win self.stopwords:
- continue
- elif win self.wdict:
- self.wdict[w].append(self.dcount)
- else:
- self.wdict[w] =[self.dcount]
- self.dcount+= 1
- defbuild(self):
- self.keys =[k for kinself.wdict.keys()iflen(self.wdict[k]) >1]
- self.keys.sort()
- self.A =zeros([len(self.keys),self.dcount])
- for i, kin enumerate(self.keys):
- for din self.wdict[k]:
- self.A[i,d]+= 1
def printA(self):
print self.A#神秘值分解矩阵为u,s,vt
u,s,vt = svd(self.A) print """\r""" print u print """\r""" print s print """\r""" print vt print """\r"""#绘图的标题和x轴和y轴的维度名称
plt.title("LSI")
plt.xlabel(u'dimention2') plt.ylabel(u'dimention3')#画文档标题
titles = ['T1','T2','T3','T4','T5','T6','T7','T8','T9'] vdemention2 = vt[1] vdemention3 = vt[2] for j in range(len(vdemention2)): text(vdemention2[j],vdemention3[j],titles[j]) plot(vdemention2, vdemention3, '.') #画词语 ut = u.T demention2 = ut[1] demention3 = ut[2] for i in range(len(demention2)): text(demention2[i],demention3[i],self.keys[i]) plot(demention2, demention3, '.')程序入口:
mylsa = LSA(stopwords, ignorechars)
for t in titles:
mylsa.parse(t)
mylsa.build()
mylsa.printA()
代码使用winPython自带spyder执行。下面部分是源码:
# -*- coding: utf-8 -*-"""Created on Wed Jun 11 17:02:39 2014@author: modified by zhouxu,add plot"""from numpy import zerosimport numpy as npfrom scipy.linalg import svdtitles =[ "The Neatest Little Guide to Stock Market Investing", "Investing For Dummies, 4th Edition", "The Little Book of Common Sense Investing: The Only Way to Guarantee Your Fair Share of Stock Market Returns", "The Little Book of Value Investing", "Value Investing: From Graham to Buffett and Beyond", "Rich Dad's Guide to Investing: What the Rich Invest in, That the Poor and the Middle Class Do Not!", "Investing in Real Estate, 5th Edition", "Stock Investing For Dummies", "Rich Dad's Advisors: The ABC's of Real Estate Investing: The Secrets of Finding Hidden Profits Most Investors Miss"]stopwords = ['and','edition','for','in','little','of','the','to']ignorechars = ''''',:'!'''class LSA(object): def __init__(self, stopwords, ignorechars): self.stopwords = stopwords self.ignorechars = ignorechars self.wdict = {} self.dcount = 0 def parse(self, doc): words = doc.split(); for w in words: #print self.dcount w = w.lower().translate(None, self.ignorechars) if w in self.stopwords: continue elif w in self.wdict: self.wdict[w].append(self.dcount) else: self.wdict[w] = [self.dcount] self.dcount += 1 def build(self): self.keys = [k for k in self.wdict.keys() if len(self.wdict[k]) > 1] self.keys.sort() print self.keys self.A = zeros([len(self.keys), self.dcount]) for i, k in enumerate(self.keys): for d in self.wdict[k]: self.A[i,d] += 1 def printA(self): print self.A u,s,vt = svd(self.A) print """\r""" print u print """\r""" print s print """\r""" print vt print """\r""" plt.title("LSA") plt.xlabel(u'dimention2') plt.ylabel(u'dimention3') titles = ['T1','T2','T3','T4','T5','T6','T7','T8','T9'] vdemention2 = vt[1] vdemention3 = vt[2] for j in range(len(vdemention2)): text(vdemention2[j],vdemention3[j],titles[j]) plot(vdemention2, vdemention3, '.') ut = u.T demention2 = ut[1] demention3 = ut[2] for i in range(len(demention2)): text(demention2[i],demention3[i],self.keys[i]) plot(demention2, demention3, '.') mylsa = LSA(stopwords, ignorechars)for t in titles: mylsa.parse(t)mylsa.build()mylsa.printA()程序执行结果: 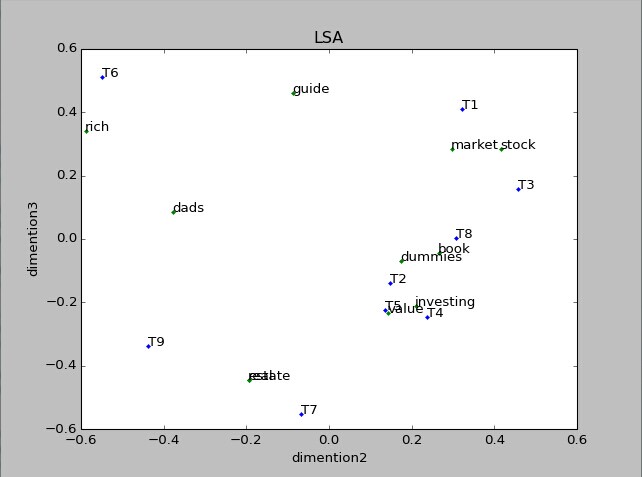
版权声明:本文博主原创文章,博客,未经同意不得转载。